El Web Scraping, es el proceso mediante el cual se nos permite extraer información de una sitio web de forma automatizada, dependiendo del nivel de complejidad del algoritmo que realicemos, podemos extraer cantidades industriales de información en cuestión de minutos.
Ese artículo, tiene como finalidad exponer el proceso de instalación de todas las dependencias necesarias para la realización del proceso de Scraping en un equipo con Debian 10.x x64, usando como lenguaje de programación Python 3.x, así como Selenium, BeautifulSoup4 y Google Chrome.
El primer comando por ejecutar actualizara la lista de paquetes disponibles y sus versiones, mientras que el segundo se encarga de instalar algunos paquetes que necesitaremos.
apt-get update
apt-get install python3 python3-pip zip unzip wget
Posteriormente instalaremos los paquetes que usaremos en Python 3.x
pip3 install selenium
pip3 install beautifulsoup4
El siguiente paso es instalar la última versión de Google Chrome para Linux, lo cual podemos hacer descargándolo e instalando, usando los siguientes comandos.
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
apt install ./google-chrome-stable_current_amd64.deb
Un paso critico es saber la versión de Google Chrome que se ha instalado, para ello ejecutamos el siguiente comando.
google-chrome --version

En mi caso la versión que tengo instalada es la 80.0.3987.163, pero esto puede ser diferente en tu instalación. Una vez que conocemos la versión de Google Chrome que tenemos instalada, debemos de ir a la siguiente página web "https://chromedriver.chromium.org/downloads" y descargar la versión de ChromeDriver que corresponda a nuestra versión de Google Chrome.
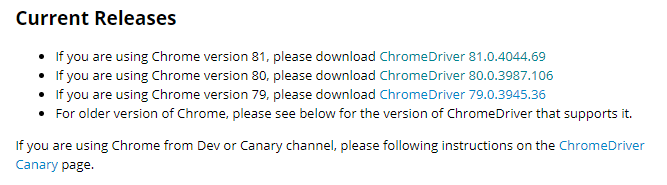
Una vez seleccionada la versión de ChromeDriver, nos redijera a una serie de enlaces, en donde dependiendo del sistema operativo que tengamos debemos de elegir la indicada, en este caso seleccionaremos "chromedriver_linux64.zip" y procedemos a copiar la dirección de enlace.
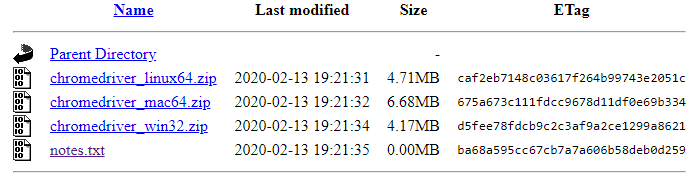
A continuación, procedemos a descargar el fichero zip, pegando el enlace que acabamos de copiar, quedando de la siguiente manera.
wget https://chromedriver.storage.googleapis.com/80.0.3987.106/chromedriver_linux64.zip
Una vez finalizada la descarga, procedemos a ejecutar los siguientes comandos, que se encargaran de instalar ChromeDriver.
unzip chromedriver_linux64.zip
mv chromedriver /usr/bin/chromedriver
chown root:root /usr/bin/chromedriver
chmod +x /usr/bin/chromedriver
A continuación, podemos ejecutar el siguiente código de ejemplo, en donde obtendremos el nombre y precio de artículos de Mercado Libre que cumplen con una serie de parámetros de búsqueda.
El resultado de la ejecución del anterior código fuente debe de ser similar al siguiente.
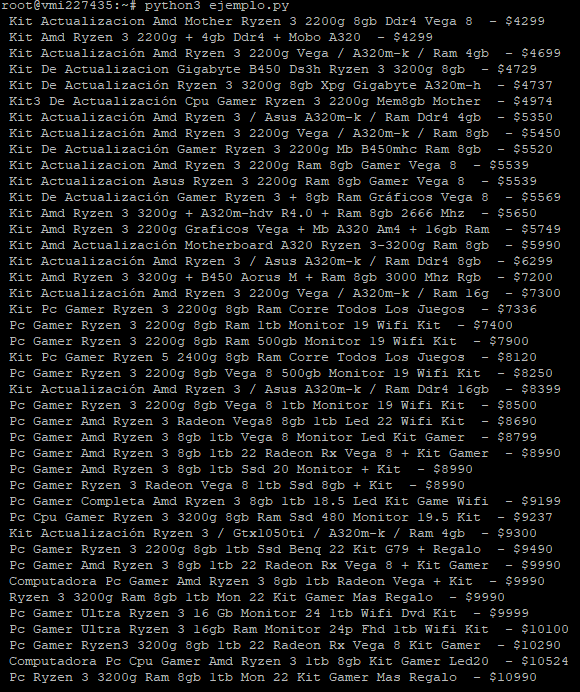
Como podemos ver, se ha realizado correctamente el scraping y hemos obtenido la información que deseábamos, posteriormente podríamos almacenarla en una base de datos o realizar análisis sobre ella.
Espero que este tutorial te haya servido y permita obtener información que te sea de utilidad.